
PowerSchool to Lakehouse: Student Data at Uncommon Schools
How Trino enables low-latency ingestion of student records at scale


Introduction
Like many Charter Management Organizations (CMOs) across the U.S., Uncommon Schools relies on PowerSchool as its Student Information System (SIS) -- the system of record for student enrollment, demographics, attendance, grades, and scheduling. While PowerSchool is critical for day-to-day school operations, it wasn’t designed for fast, large-scale analytics use cases.
Under the hood, PowerSchool stores its data in an Oracle database, which makes extracting large tables -- like Students -- surprisingly slow when using conventional approaches.
In this post, I’ll walk through how we reduced ingestion time for the Students table from nearly 50 minutes to under a minute. We achieved this by migrating from a custom Python-based pipeline to Trino, enabling significantly faster data access and simpler ingestion logic. Along the way, I’ll share a few practical techniques to speed up data extraction -- not just in Oracle, but in any database system that supports procedural logic.
This work builds on ideas we explored in our earlier post, Trino + dbt: Simplifying ELT with Pure SQL, where we showed how combining Trino and dbt can simplify ingestion, improve reliability, and unify ingestion with transformation workflows. Here, we take that foundation further -- focusing on performance, real-world constraints, and how to make ingestion not just simpler, but dramatically faster.
The Original Pipeline: Where We Started
Our initial approach was built around a containerized extraction layer. We created a custom Docker image based on an Oracle Instant Client setup, which allowed us to connect directly to the PowerSchool Oracle database and run extraction queries. This image included Python, SQL*Plus, and a set of internal scripts used to execute parameterized queries and export data.
We orchestrated everything with Airflow, where each table ingestion was defined as a separate task in a DAG. Each task would spin up a container (via ECS/EKS) using our custom operator, ensuring that extraction workloads didn’t run on Airflow workers themselves but instead executed in isolated pods. This design gave us scalability and parallelism—but also introduced operational complexity.
To control what data gets extracted, we relied on SQL templates. Each table had its own query template, dynamically parameterized (e.g., by PowerSchool instance), and executed inside the container. For example, the Students table template included not only direct column selections, but also calls to Oracle PL/SQL functions like ps_customfields.getStudentsCF.

These functions are part of PowerSchool’s internal logic layer and allow access to data that isn’t physically stored in the base tables. While this gave us flexibility and completeness, it also came at a significant performance cost—each function call is effectively an additional computation executed per row.
Over time, several issues with this approach became clear:
Lack of lineage and validation: Changes to SQL templates were difficult to track and validate against downstream models. A simple column removal could silently break transformations later in the pipeline.
Operational overhead: Each table required its own Airflow task and container. With ~30 tables, this meant dozens of parallel pods, making logs harder to read and increasing pressure on orchestration infrastructure.
Performance bottlenecks: The biggest issue—queries were slow. Very slow. Extracting the Students table for a single instance could take up to 50–60 minutes, largely due to heavy use of PL/SQL functions and row-by-row processing.
In short, while the pipeline worked, it wasn’t scalable, transparent, or fast enough for our needs.
The New Approach: Fast Ingestion with Trino
To address the limitations of our original pipeline, we leaned into the approach we described in our previous post, Trino + dbt: Simplifying ELT with Pure SQL. The core idea is simple but powerful: move ingestion logic into SQL, unify it with transformation workflows in dbt, and let Trino handle execution across systems.
This shift solved several problems at once.
First, unpredictable production issues became much easier to manage. By bringing ingestion into dbt, we gained lineage, dependency tracking, and the ability to validate changes before they reach production. Instead of discovering issues at runtime, we can now catch them during development or CI – exactly the gap we highlighted in our earlier work.
Second, we eliminated the overhead of “millions of tasks and pods.” Instead of running one Airflow task per table (and spawning dozens of containers), we now have a single Airflow task that triggers a dbt run. Within that run, dbt executes multiple models concurrently using threads – all inside a single pod. This dramatically simplifies orchestration, improves observability, and reduces load on both Airflow and our container infrastructure.
But the biggest win came from query performance.
In the new approach, the ingestion logic is written as a dbt model that uses Trino’s system.query to push down execution directly to Oracle. Instead of relying heavily on row-by-row PL/SQL function calls, we restructured the query to:
Replace expensive function calls where possible with joins (e.g., leveraging studentcorefields, vwstudentcorefieldsuc, and other tables instead of repeatedly calling ps_customfields.getStudentsCF)

The result is a much more efficient execution plan: fewer function calls, better use of joins, and improved parallelism across databases.
Combined with Trino’s ability to execute queries concurrently and dbt’s threaded execution model, this reduced the ingestion time for the Students table from nearly an hour to under a minute.
Just as importantly, the pipeline is now simpler, more maintainable, and fully transparent. Instead of spreading logic across Docker images, Airflow tasks, and SQL templates, everything lives in version-controlled dbt models—fully integrated with the rest of the data platform.
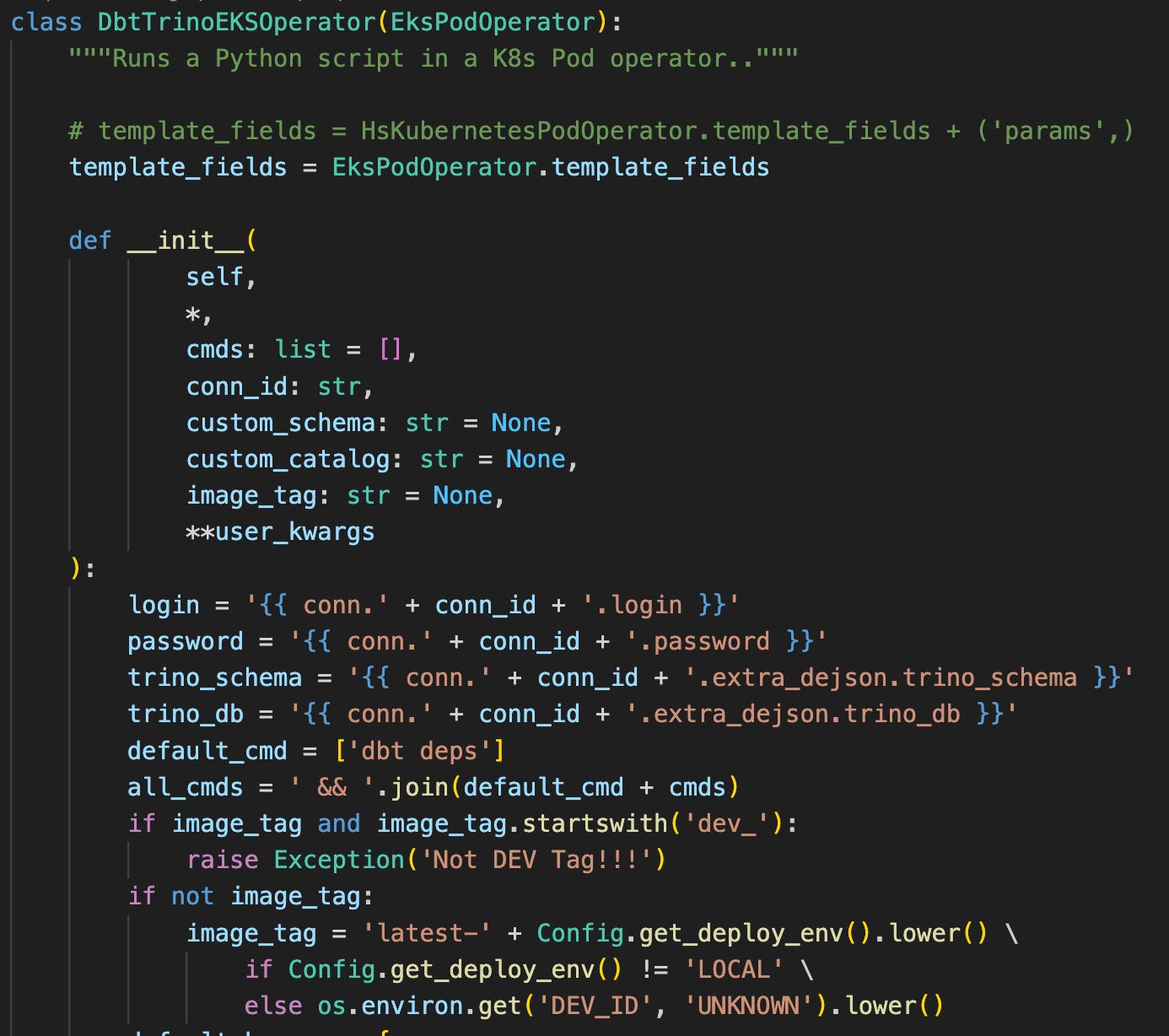
To tie everything together operationally, we also introduced a lightweight custom Airflow operator that runs dbt + Trino workloads inside a single Kubernetes pod:
Summary
Uncommon Schools’ data team cut ingestion time for PowerSchool student records from nearly an hour to under a minute by replacing a custom Python/Docker pipeline with Trino and dbt. The original setup relied on containerized Oracle extractions, row-by-row PL/SQL function calls, and one Airflow task per table — functional, but slow, hard to maintain, and operationally expensive. The new approach moves ingestion logic into dbt models, uses Trino to push queries directly down to Oracle, and replaces costly function calls with efficient joins. The result is a faster, simpler, and fully version-controlled pipeline where lineage, validation, and transformation all live in one place.